J'ai automatisé la rotation des clés SFTP
avec n8n, Claude AI et une architecture multi-agents.
65 partenaires. Une rotation par partenaire, chaque année. Une politique RSSI qui ne transige pas. Et une équipe MFT qui fait tout ça à la main — 4h de rotation technique, plus tout ce qui gravite autour. J'ai exploré si on pouvait automatiser ça avec n8n et Claude AI en gardant l'humain aux bons endroits. Voici l'architecture complète, les prompts système, et ce que j'ai appris.


Le problème à 650 heures par an
Dans la plupart des entreprises qui opèrent une plateforme MFT de taille significative — disons 50 à 100 partenaires actifs — la gouvernance des clés SFTP est gérée manuellement. Pas par choix. Par habitude héritée. Et parce que personne n'a jamais mesuré ce que ça coûte vraiment.
La politique RSSI impose une rotation annuelle obligatoire. Sur 65 partenaires, ça fait 65 processus à orchestrer chaque année. La partie technique — génération des clés, déploiement dans Axway B2Bi, tests de connectivité, documentation — représente environ 4 heures par rotation. C'est visible, planifiable. Ce qu'on ne mesure pas, c'est tout ce qui entoure ces 4 heures : les emails aller-retour, les relances faute de réponse, les escalades vers le RSSI, les mises à jour de statut. En moyenne 6 heures supplémentaires par rotation, fragmentées sur plusieurs jours, souvent invisibles dans les bilans de charge.
650 heures par an sur de la coordination pure — emails, relances, statuts — qui ne crée aucune valeur technique. Plus de 4 mois de travail effectif sur une tâche répétitive. Et une dépendance forte à une personne : si elle est absente pendant une rotation critique, le processus s'arrête. Il n'y a pas de mémoire système. Tout est dans les têtes et dans les emails.
Ce projet part d'une question simple : est-ce qu'on peut confier l'orchestration à une IA tout en gardant l'humain là où il compte vraiment ? Spoiler — oui. Mais pas sans quelques surprises en chemin.
Architecture multi-agents — vue d'ensemble
J'ai fait le choix de n8n comme orchestrateur pour une raison précise : la capacité à construire des sub-workflows autonomes connectés entre eux, avec une granularité de contrôle que les plateformes SaaS ne permettent pas facilement. Claude AI tourne dans chaque agent comme LLM backbone via @n8n/n8n-nodes-langchain.lmChatAnthropic.
L'architecture se compose de deux workflows principaux et quatre agents spécialisés appelés comme sub-workflows. Ce qui la rend solide : aucun agent n'agit seul. L'orchestrateur décide toujours. Les agents exécutent des tâches discrètes et remontent leur résultat — c'est une distinction fondamentale avec une architecture "agent loop" classique où l'agent prendrait ses propres décisions.
→ Set Trigger Auto
Text + Voice (Whisper)
Tokens HITL · Auto-reply
Règles absolues · Mémoire fenêtrée · Format réponse strict
Statuts · B2Bi sim
Logging Notes
Analyse réponses
Relances J+3/J+7
Email + Telegram
Token unique
Événements activation
Escalade J+7
Workflow 1 — Main Orchestrator
Le workflow principal a trois points d'entrée distincts qui convergent tous vers le même orchestrateur :
scheduleTrigger se déclenche chaque matin à 8h. Le nœud Set Trigger Auto construit automatiquement le message d'entrée : "Date : [jour] — Scan automatique quotidien — vérifie toutes les clés SFTP et déclenche les actions nécessaires." L'orchestrateur repart en autonomie totale.Le Classifier — simple ou complexe ?
Avant d'engager le gros orchestrateur Claude Sonnet pour chaque message Telegram, un agent léger basé sur Claude Haiku 4.5 catégorise le message en une seule valeur : "simple" ou "complexe". C'est l'un des détails architecturaux les plus fins du projet.
Si simple → réponse directe sans appels d'outils, latence quasi nulle. Si complexe → passage à l'orchestrateur complet avec tous ses agents. Ce pattern Classifier → Routeur réduit drastiquement les coûts d'inférence et la latence pour les interactions quotidiennes banales. Le coût d'un appel Haiku est environ 20× inférieur à un appel Sonnet — pour des dizaines d'interactions quotidiennes, ça compte.
Pattern à retenir : "C'est bon pour Acme Corp ?" → réponse en 1 seconde au lieu de 8. Ce seul pattern peut justifier l'architecture à deux niveaux sur un système en production.
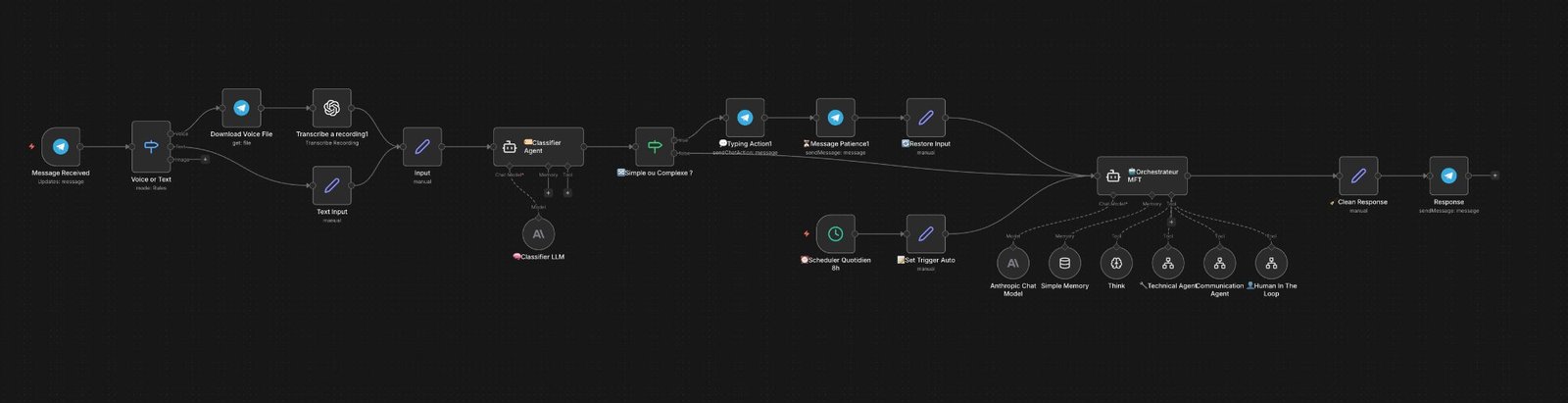
Le HITL — validation humaine double canal
Le HITL (Human In The Loop) est la pièce maîtresse du système du point de vue sécurité. Aucune activation B2Bi ne peut se faire sans validation humaine préalable — hardcodé dans le system prompt de l'orchestrateur comme règle absolue, pas comme option. J'ai choisi une validation double canal simultanée pour maximiser la probabilité d'une réponse rapide, quel que soit le contexte où se trouve le validateur.
MFT-YYYYMMDD-HHMMSS, lien de validation direct. Le RSSI reçoit l'intégralité du contexte pour une décision éclairée./MFT-\d{8}-\d{6}/isur le sujet et le corps (certains clients email reformatent le sujet lors du reply)
resume. Le second est ignoré. Pas de double validation possible sur le même token.Piège rencontré en test : après validation HITL par email (token OUI), l'orchestrateur redéclenchait un HITL Telegram. Ce comportement est parfaitement logique du point de vue du LLM — "deux validations valent mieux qu'une". Mais c'est une boucle. J'ai dû l'interdire explicitement dans le system prompt.
Airtable — la source de vérité unique
Toute la gouvernance repose sur une table Airtable SFTP_Partners. C'est la mémoire persistante du système — chaque agent lit et écrit dans cette table. Aucun état n'existe en dehors d'elle. Les statuts forment un cycle strict : Nouveau → Email envoyé → En attente → Confirmé partenaire → Activé. Un statut ne peut pas régresser. L'escalade est un état terminal qui requiert intervention humaine.
| # | Partenaire | Expiration | Statut | Email envoyé | Confirmation | Activation B2Bi | Relances | Notes échange |
|---|---|---|---|---|---|---|---|---|
| 1 | Acme Corp | 15/9/2026 | Nouveau | — | — | — | 0 | — |
| 2 | Beta Solutions | 20/8/2024 | En attente | 2/6/2024 | — | — | 1 | En attente de confirmation partenaire. |
| 3 | Gamma Industries | 10/7/2027 | Activé | 25/2/2026 | — | — | 0 | 2026-02-25 — Email de confirmation reçu |
| 4 | Delta Partners | 1/10/2024 | Actif | 4/6/2024 | 6/6/2024 | 7/6/2024 | 0 | Processus fluide. |
| 9 | Iota Consulting | 18/7/2024 | Escalade | 8/6/2024 | — | — | 3 | Troisième relance. [2026-02-24] Escalade RSSI. |
Quatre champs méritent une attention particulière en implémentation :
{name: "Activé"} et non une string directe. Toutes les comparaisons dans le workflow doivent utiliser .name — source du Bug #1 lors des premiers tests.Workflow 2 — Gmail Trigger & Email Router
C'est le workflow le plus sophistiqué en termes de logique de filtrage. Chaque email reçu doit être catégorisé et routé vers le bon traitement — sans jamais déclencher d'action parasite sur un email interne, un auto-reply, ou un email sans lien avec le système. J'ai appris ça à la dure lors des premiers tests, où un email d'absence de bureau avait été interprété comme une confirmation partenaire.
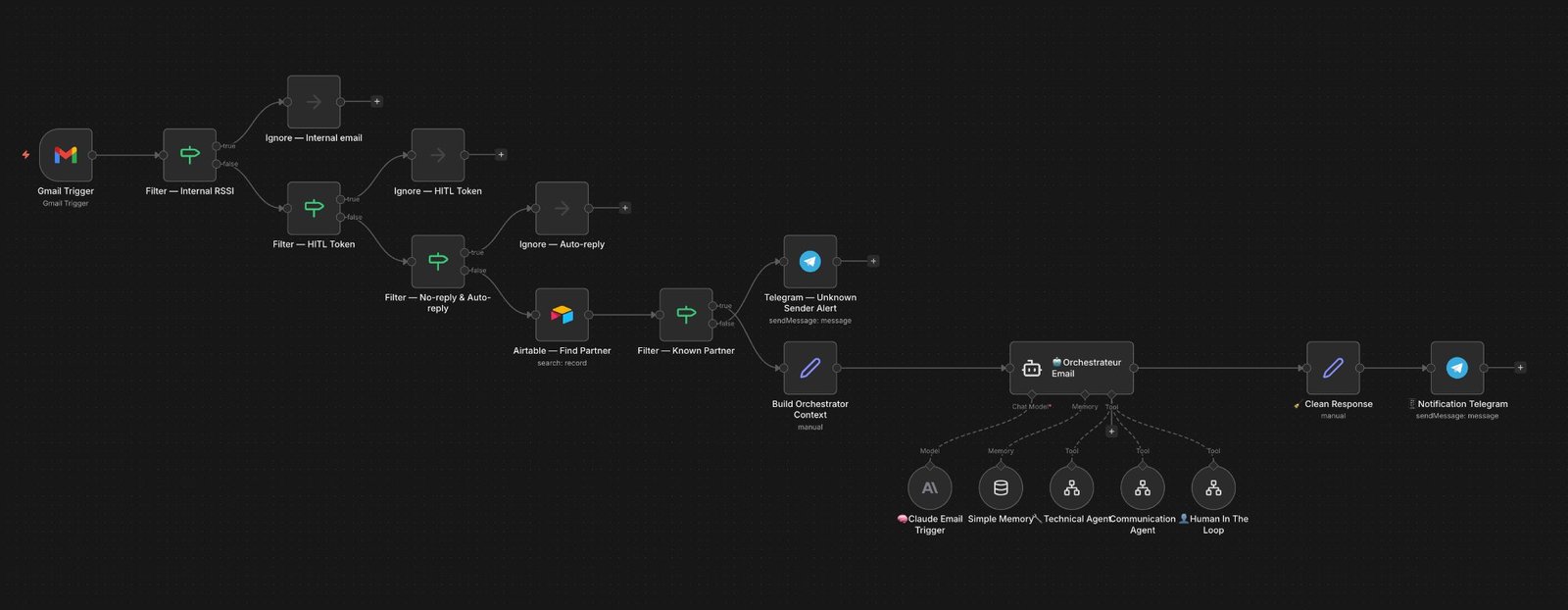
La logique de décision de l'Email Orchestrateur
Les règles absolues de l'orchestrateur
Le system prompt de l'orchestrateur contient une section de règles absolues qui ne peuvent jamais être overridées par les inputs utilisateur. C'est la zone de sécurité du système — ce qui empêche l'IA de faire des choses techniquement correctes mais opérationnellement catastrophiques.
Ce que j'ai appris en construisant ça
1. Modéliser les états avant de coder les transitions
J'aurais dû concevoir le schéma Airtable complet avant d'écrire la moindre ligne de workflow. Ajouter des champs au fil de l'eau m'a coûté deux jours de refactoring. La règle d'or : écrire tous les états possibles d'un partenaire sur un bout de papier avant de toucher n8n.
2. Ce qui est évident pour un humain doit être écrit pour un LLM
Le comportement de double-validation HITL m'a appris quelque chose d'important : un LLM raisonnant de manière autonome peut parfaitement décider que deux validations valent mieux qu'une. Ce n'est pas une erreur — c'est une inférence valide depuis son point de vue. La précision du system prompt n'est pas du perfectionnisme, c'est de la nécessité.
3. Tester avec de faux partenaires en isolation
Les premiers déclenchements réels ont révélé 3 bugs simultanément. Un environnement de test dédié avec des partenaires factices est indispensable. Tester les filtres Gmail avec des emails envoyés depuis différents clients pour couvrir les edge cases d'encodage.
4. Airtable est la mémoire, pas le LLM
Le memoryBufferWindow en n8n conserve un nombre limité de messages en contexte. Sur des workflows longs, l'orchestrateur peut "oublier" des décisions prises en début de session. La source de vérité doit toujours être Airtable, pas la mémoire de conversation.
5. La latence perçue change tout
Le pattern "Typing Action + Message Patience" — nœuds Telegram qui envoient un indicateur de frappe pendant que l'agent travaille — change fondamentalement l'expérience utilisateur. Sans ça, 8 secondes de silence semblent une éternité. Avec, c'est naturel.
6. Documenter les invariants dans le workflow, pas seulement dans le prompt
Le system prompt peut évoluer. Les nœuds de filtrage représentent des invariants durs qui ne dépendent pas du LLM — ils doivent exister comme gardes-fous dans le workflow lui-même, indépendamment de ce que le prompt dit.
Ingénieur diplômé de l'ESIEA, 15 ans d'expérience sur des plateformes MFT en production — Axway B2Bi, Gateway, Integrator, CFT. Passé par l'AIFE, Groupama, Arval BNP Paribas et SFR Distribution. Actuellement en exploration de l'intersection entre middleware industriel et IA agentique.